The post Pryv.io Personal Data Mapping to enable automatic integration with existing warehouses appeared first on Pryv.
]]>Pryv.io Personal Data Mapping to enable automatic integration with existing warehouses.
Integrate existing data warehouses with Pryv.io privacy back-end:
- Make legacy systems (warehouses) easy to integrate with new external systems within a privacy-compliant environment.
- Significantly reduce time and errors managing data-subject requests.
Pryv developed and commercialized a privacy-by-design middleware system that provides full, innovative personal data life cycle management. This technology allows for privacy compliance, interoperability and data sharing to a granular-level, using transparent, unambiguous enforcement of consent applied on a data set.
Pryv.io Data Mapping provides companies with existing data warehouses the means to adopt faster innovation, integrate real-world personal data and build better personalised services, all within a transparent and privacy-compliant environment.
Existing systems usually face major hurdles integrating with external solutions with the synchronisation of very big datasets and the transfer and storage of multiple copies of sensitive data. Pryv.io Data Mapping allows:
- to benefit from the capacity of privacy-by-design models;
- map dynamically existing datasets in a transparent and unambiguous form, presented to an individual for his enlightened consent;
- unlock the capacity to offer privacy on legacy datasets.
Request A Presentation
Current status for managing data-subject requests on personal data access and processing by systems without privacy-by-design architecture:
Today, initiating a NEW data processing in organizations with legacy systems involves time consuming processing for the Data Protection Officer (DPO) to scope the necessary datasets, collect consents and verify compliance with applicable regulations. Furthermore, it requires manual intervention of technicians to extract datasets. Multi-employees interaction and manual processes are prolonged, lack efficiency and generate errors. Such processes would not be acceptable in the short-mid term. Investments in innovation and automation must be considered. (Pic. 1)

Managing data-subject requests on personal data access and processing by implementing Privacy-by-design solutions
Privacy-by-design solutions digitalize consent collection and offer effective control over the personal data life cycle. Pryv.io provides a privacy-by-design framework to interact with personal data. This framework only operates on data it controls. (Pic.2) Still, this solution requires the data to be fully copied and synchronized from/with the legacy system. This process is not optimal for large data warehouses, data lakes and highly dynamic data sets.

Pic.2 Managing data-subject requests on personal data access and processing by implementing Privacy-by-design solutions
Solution: Personal Data Mapping to enable automatic integration with existing warehouse for managing data-subject requests on personal data access and processing
To meet the needs of mapping large data warehouses, data lakes and highly dynamic data sets, Pryv has developed a new technology that maps dynamically existing datasets in a transparent and unambiguous form to be presented to an individual for his enlightened consent.
“Unlocking the capacity to offer privacy on legacy datasets allows us to provide our services to a much broader set of companies handling personal data, which is important since the older ones are more in need of an up-to-date system regarding privacy regulations.” says Pierre-Mikael Legris, CEO and co-founder of Pryv SA.
Privacy-by-design solutions digitalize consent collection and offer effective control over personal data life cycle. Pryv.io provides a privacy-by-design framework to interact with personal data. To operate, this framework must stand as a “gateway” to interact with personal data. Including Dynamic Mapping. On Existing Datasets allows to benefit from privacy by design for new over existing data sets. (Pic.3)

Pic.3 Personal Data Mapping to enable automatic integration with existing warehouse for managing data-subject requests on personal data access and processing
To learn more about how Pryv.io Dynamic Data Mapping will resolve your personal data management needs and facilitate automatic integration of personal data mapping with your existing warehouses contact us at: https://github.com/pryv
For more features by Pryv.io, visit: https://pryv.github.io/www/tag/features/
Developer resources: https://pryv.github.io/
Commercial applications: https://pryv.github.io/www/news-list/
The post Pryv.io Personal Data Mapping to enable automatic integration with existing warehouses appeared first on Pryv.
]]>The post “Data Integrity” is key to safeguard data, trust and business reputation appeared first on Pryv.
]]>Once lost, trust cannot be easily found, or not at all.
Data tampering attacks are a serious threat. And as recent news indicates an upsurge of cyber-attacks against personal data-fueled businesses worldwide, one that should be taken seriously. Imagine the repercussions of a clinical trial results based on data altered by an attacker.
Data can be tampered with in many ways.
In the worst cases, these alterations may even remain undetected. So how can you ensure that data has not been subject to unauthorized changes along the way?
Data Integrity
Data integrity refers to the accuracy and consistency (validity) of data over the data lifecycle. It means that the data, from the time it was collected to the time it was stored, used, shared, archived and deleted, can be trusted to be accurate and free from tampering.
Regulations such as the GDPR or Swiss DPA in particular provide for such a requirement as a key principle to ensure that data is adequately protected, which is of utmost importance when it comes to the collection and usage of personal data assets.
By ensuring data integrity, companies ensure that data is exactly as it should be at any given time, which is key for health data, medical information, or contractual documents.
(eg.: with a digital signature (eConsent) for Clinical Trials DCT), etc)
How is Data Integrity achieved by Pryv.io? – Generating a checksum for all data uploaded
When a document or information is created or modified on Pryv.io, a receipt is issued with a “checksum”, which can then be used to detect unexpected modification.
The receipt does not expose any personal data, but simply serves as proof of integrity. You can think of this receipt (checksum) as your data’s fingerprint.
This ability to check for data accuracy and consistency can be very valuable in the context of Remote Clinical Trials. For example: Tom, a participant of the trial, uploads a document on a dedicated online platform to be shared with Dr.Jones, his investigator:
- After the upload is completed, a receipt is issued to Tom with the following checksum: “1582054665”.
- Tom can share the receipt (checksum) with Bob separately. And tell Bob that the document he will get must have the same checksum (“1582054665”).
- Or, Bob could compute the checksum when he receives the document and send it to Dr.Jones, who can then confirm that the “fingerprints” match.
- If a single bit of the document is changed, the checksum will be fully different.
What added value does it bring?
Whether on purpose or by accident, compromising data integrity can not only result in serious risks for the data subjects, but also put the entire company’s reputation and operations at risk. At any given time, individuals using a platform, or an app built on Pryv.io can verify that the data has not been subject to any unauthorized change.
Data Audit & Integrity?
Audit logs maintain a full and complete history of every change that has been made on a piece of data, by whom and when. An audit log is the simplest, yet also one of the most effective forms of tracking temporal information. Any time something significant happens, a record indicating what happened and when it happened, is generated.
Coupled with this audit feature and versioning of Pryv.io, companies can rebuild the data lifecycle to prove the genuinity of the data.
Blockchain – Full data integrity support for Pryv.io enables a new level of trust and confidence between our customers and their partners
The Pryv.io data integrity mechanism is designed to be coupled with a timestamping solution or a blockchain. In that case, the blockchain would keep all the receipts for public (or private) consultation.
Data worths nothing if not trustworthy
At Pryv we continuously work on advancing Pryv.io functionalities to ensure we deliver an outstanding technology not only to meet technical and legal requirements, to ensure confidentiality and trustworthiness of data, but embed trust in any aspect of building a strong relationship with your customers.
Stephanie & Evelina
Online sources:
- https://gdpr-info.eu/art-5-gdpr/
- https://gdpr-info.eu/art-32-gdpr/
- https://www.fedlex.admin.ch/eli/cc/1993/1945_1945_1945/en
- https://www.fedlex.admin.ch/eli/cc/1993/1962_1962_1962/en
- https://www.fortinet.com/resources/cyberglossary/cia-triad
- https://en.wikipedia.org/wiki/Checksum
The post “Data Integrity” is key to safeguard data, trust and business reputation appeared first on Pryv.
]]>The post Master the GDPR Compliance Checklist with Pryv.io appeared first on Pryv.
]]>It’s not news: from two years already, if you’re a company operating with EU citizens personal data, you have to comply with the GDPR (General Data Protection Regulation). Effective since 25 May 2018, the regulation sets out a number of legal obligations to be met in terms of privacy requirements and generous fines to be paid for those who don’t play by its rules. Yet in spite of its not-so newness, a lot of questions are still arising when it comes to GDPR compliance: how to achieve it? Where to start? How to leverage its requirements into a competitive advantage?
Master the GDPR Compliance Checklist with Pryv
While lots of companies see the GDPR as a boring legal conundrum to solve, it is actually one of the best frameworks you can use to flourish and scale up your business. That is of course, assuming you do it smartly; we bet you would rather use your resources to enhance your application than have them stuck finding a way to answer on the user’s rights on their data: how to execute their consent, where to store their data… getting a copy of the data ready, process to delete it? At the end of this article, you’ll be the one ready to master your GDPR compliance and know how Pryv.io’s capabilities can help you thrive in the blooming personal data economy.
GDPR 101: a checklist to achieve compliance
To make it easier for companies to navigate the storm of the GDPR data protection and privacy requirements, the gdpr.eu website provides easy-to-understand, compliance guidance through a variety of digital content aiming at explaining and/or highlighting the specifics of the regulation. Especially, they provide a free, online GDPR Compliance Checklist that businesses can use as a framework to achieve their own compliance. This is exactly where you want to start when asking: “Am I ready for the GDPR?”
Divided in four parts, the checklist sets out a list of 19 things to be checked or done (preferably before going to market!) in order to reduce the risks of regulatory penalties.
The checkups are regrouped by privacy-related “themes”:
- Lawful basis and transparency
- Data Security
- Accountability and governance
- Privacy rights
In the following, we will show for each of these checkups how you can leverage our technology to achieve GDPR compliance while increasing your business efficiency.
GDPR Compliance Checklist @ glance, with Pryv
Pryv.io is an extensible personal data life-cycle management platform specifically engineered to empower businesses to rapidly create and scale breakthrough, GDPR compliant applications.
A lot of organizations are skeptical about involving a third-party for their privacy – we get it.
So let’s be clear: we don’t access or host any data. All we do is to provide our clients with a ready-to-use, scalable piece of code/software that can be used to rightfully collect, store, share and use personal data. Moreover, you can even choose where you want the data to be stored for each user separately, so it is both safe and compliant with all relevant data residency laws. Pryv.io will then be deployed on the servers and/or infrastructure of your choice.
GDPR Compliance Checklist |
How Pryv helps you solve it |
Lawful basis and transparency |
|
|
These checkups will help you ensure a lawful, transparent collection and processing of personal data.As for our part, we provide you with a comprehensive and easy-to-scale Software Solution that you can use to easily keep track of what information you process as your business grows. If your legal justification is consent, the Pryv.io eConsent mechanism will allow you to keep track of every consent and related data-accesses per user.
As a plus, the Pryv.io data model is designed to enhance data aggregation, thus allowing for increased business efficiency on your side. On demand, we also help our clients with their data strategy & privacy policies. |
Data Security |
|
|
This part is about ensuring that the personal data you collect will be safe, secured and well protected. As said before, we do not access or host any data. Using Pryv.io will thus not jeopardize your internal security; at best, it can also help you achieve it. Our software is privacy-by-design and provides encryption for data “at move” (during transmission). For data at rest: Pryv.io supports client-side mechanisms so you can add as many security layers as you need.
Pryv.io’s segmentation of data and aliasing feature (Release Q1 2021) also allows to selectively share data pseudonymized or anonymised if there is no data that allows identification. In addition, Pryv.io’s audit module provides information to security systems that can be used to detect a data breach, and further help you identify which data has been leaked. As our client, you will also benefit from our partnerships with data security and hosting providers, such as Build38 and Euris Health Cloud®. |
Accountability and governance |
|
|
Someone has to ensure that the personal data you collect is properly handled throughout your organization and beyond.
Pryv.io can help you ensure that he/she understands what is happening in terms of data within your organization. Like banks that provide detailed reports of all transactions in time, classified in bank accounts, the Pryv.io data model provides all data in “time series” contextualised and classified in streams. It is designed to provide the same readability and transparency as your bank report, so anyone could make decisions and check its execution with a minimum of effort. In this context, Pryv.io can be used as a data controlling tool to be operated by your DPO. |
Privacy rights |
|
|
Last but not least, this part is about ensuring that you provide your users with the means to enact their rights.
While it is your job to ensure that your customers can enact their rights, on our side, we provide you with the functionalities to execute them. Built with a user-centric approach, Pryv is designed to ensure these functionalities while maximizing software performance and business efficiency. In particular: -> Pryv.io allows you to provide your users with the option to backup their data on their computer or transfer it to another company (data portability, as requested by checkup #17). (For example, we developed a ”blue button” app, which will allow the data to be exported as JSON files and packed inside a password protected zip file in one click.) -> Our API methods allow our customers to easily correct/update/delete data inside a user’s account. -> Pryv.io proposes a specific mode that enables isolation of per-user data in back-ups for deletion. Our software is privacy-by-default (default opt-out). This is made to ensure that your users have an explicit choice as to accept or object to the processing of their data. All processes have a 1-to-1 relationship with the users of the App, allowing them to update or revoke their consent at all times. This is dynamic consent. As a plus: you can further de-risk your compliance with the Pryv.io data-audit embedded feature – so that beyond allowing your users to benefit from their lawful rights, you can also prove that they were respected and executed rightly. |
Focus on your core business knowledge and let Pryv.io optimize your organization’s resources for a responsible, efficient, and lawful collection, use, sharing and disposal of information.
In addition, you will be able to benefit from Pryv.io’s latest features: webhooks for real-time data notifications, and many others that will help you boost your business’ success!
Still skeptical? Take a look for yourself: because we believe transparency is key when it comes to privacy, our software is also available in Open Source since this summer.
For all other questions or to book a demo, contact us directly at: https://pryv.github.io/www/contact/
Yours,
Pryv Team
The post Master the GDPR Compliance Checklist with Pryv.io appeared first on Pryv.
]]>The post The Personal Data LifeCycle, sorted out by Pryv. appeared first on Pryv.
]]>Companies tend to put their best resources and minds on getting the best product for their users – it’s normal. But in doing so, a number of organizations are failing at organizing their data lifecycle. First, it is not a simple task: it’s a blend of legal, IT and business-logic actions which need to be designed to meet current data and regulatory requirements, as well as to last over time.
Also, very often, while focusing too much on the data processing stage, organizations forget about the importance of carefully managing the data at all of its stages, which can rapidly become an issue.
Data without proper management can not only create privacy and security gaps, but also position the entire operations of the company at risk. Not to mention the fact that you would probably get more insights from the data once you’ll have a clear picture of your company’s entire data economy.
Hence, having a proper oversight of the data lifecycle stages and how to implement them within your organization is absolutely essential: not only to achieve business efficiency and properly address all relevant privacy and data protection requirements, but also to ensure seamless interoperability and scalability.
- Does your system have interoperability capabilities to allow easy integration and manage diverse data-sets? Can it scale over time?
- Does your system properly address all the current regulatory requirements? Are you ready to adapt to forthcoming changes?
- Is your company prepared to efficiently handle users’ data requests: “where is my data? Who does access it? Can you delete it?”
- Can you prove that you have executed your users’ rights and consent correctly?
At Pryv, we made it our core business to answer these critical questions, and made available for businesses a ready-to-use solution to manage personal data, rightly.
Meet Pryv.io: Simple, yet remarkably powerful personal data management platform.
Pryv.io is an extensible personal data lifecycle management platform specifically engineered to empower businesses to rapidly create and scale breakthrough, privacy compliant products.
- Its data model is precisely designed to aggregate and distribute multiple sources of information. The API allows you to easily collect and store any type of personal data.
- Dynamic consent and auditing capabilities ensure that beyond allowing your users to benefit from their lawful rights, you can prove that they were respected and executed rightly.
- Decentralized and per-user data storage distribution are also included as must-have features to guarantee your business scalability across legal environments.
Focus on your core business knowledge and let pryv.io optimize your organization’s resources for a responsible, efficient, and lawful collection, use, sharing and disposal of information.
(1) Data Collection: Seamless connectivity, interoperability with no-limits.
Pryv.io allows you to collect data from any source of information, including, but not limited to:
- Internet of things (IoT) devices
- Mobile applications
- Server-side data collection for web-enabled applications
- Any other source
It further supports collecting, aggregating and storing data, such as: files, health metrics, locations, audio samples, notes, pictures, activities… you name it! So that you can collect any type of data you need to fulfill the purpose of your organization – today, tomorrow, and beyond.
While we already implemented a various number of Standard Types for the data, our customers are allowed to design their own data models and implement it under Pryv’s conventions if needed.
To know more about how Pryv.io allows you to collect and aggregate data from multiple sources for a subject, you can take a peek at our Data Modelling Guide which further explains Pryv’s Data collection.
Pryv.io High Frequency: unleashing IoT Connectivity with High Throughput Data Ingestion.
In case data is collected by IoT devices, Pryv goes even deeper and unleashes IoT Connectivity with High Throughput Data Ingestion. Ingesting data at almost any speed your underlying system allows, making storing data at high frequency a breeze for your organization.
(2) Data Aggregation and Structure: All data is kept per-user, total control over privacy
The value of combining a robust amount of data and diverse datasets is essential for providing personalized offerings. We understand that and offer you a way to do it efficiently, compliantly.
Inherently, all data is collected at a specific moment in time. We thus designed a data structure that approaches all collected data as “time-stamped data”, providing companies with an interoperable structure that is easy to understand and work with.
This extendable and scalable solution allows for unlimited types of data to be structured in a unified model and organized hierarchically, enabling the data to bring meaningful insights to organizations.
Based on “streams” and “events”, pryv.io provides a unique ontology (Pryv SA know-how and trade secret, labelled as fully “Swiss made” technology) that allows for interoperable structure designed to serve Privacy and Development Teams.
Pryv.io Data Model: Data structures for interoperability
To let data be easily understood and exchanged across systems, we provide an open directory of standard types, which we recommend developers use when interoperability is a concern (read more)
(3) Data Storage: Decentralized design to span the globe with no bottleneck.
Organizations should always know what data they are collecting, who can access it, and who will effectively access it before making any decision about where the data should live.
With Pryv.io, you can easily store data into a distributed environment to enable local (on- premise/per choice) Regulations Compliance, and even create installations that span the globe and co-locate the data with the users’ legislation.
Based on a powerful distributed model, users are distributed among servers with no global bottleneck.
Each user account can be served by a different server, which can be located anywhere. The capabilities are set by the architectures in terms of bandwidth and storage. The architecture is designed according to the client’s needs.
(4) Data Sharing: Dynamic Consent and Protected Access.
A clear sharing mechanism allows giving access to selected pieces of data to anyone, while still retaining full control over the data. Pryv.io enables you to define accesses with different levels of permissions for third-parties to interact with your data, or only particular folders of your data.
Through a sleek “campaign manager”, it manages access permissions of multiple accounts, making storing accesses of multiple data subjects that gave you their consent easier. The perfect solution to be able to retrieve all data accesses and facilitate data aggregation.
Learn more about Pryv Consent Aggregation on our dedicated web page.
(5) Data Audit: Transparency at a glance.
Pryv.io provides access to audit logs and pre-built compliance services. The Audit logs keep track of details about the actions performed by clients against Pryv.io accounts through the Pryv.io API.
A full audit trail documenting interaction with the data is embedded in the solution: who does create the data-point, when and under what granularity a consent is given. A proof that any access is authorized is provided by listing all the processes applicable under GDPR, such as: who did access and review the data and when.
Pryv.io facilitates compliance with existing and future data protection and privacy regulations on a global scale.
(6) Data Retrieval: protected backups for your users.
Pryv.io allows you to provide your users with the option to backup their data on their computer.
For example, we developed a ”blue button” app, which will allow the data to be exported as JSON files and packed inside a password protected zip in one click.
(7) Data Deletion: Data erasure on demand – proven and safe.
One of the biggest issues with the data collection is that very rarely it is made clear for how long the data will be stored before being deleted. Only a few businesses provide their users the option to use the “download” and “delete” buttons.
Pryv.io proposes a specific mode that enables isolation of per-user data in back-ups for deletion.
Pryv.io Lifecycle Data Management Platform allows you to manage your data, rightly.
While your core business revolves around data collection, ours revolves around you. We thus made sure that our platform not only offers you a successfully proved solution, but also addresses all your concerns:
– Deploying Pryv.io on your infrastructure is made within minutes.
– We continuously develop sleek adoption tools that make it easier for you to work with your desired data-sets. Documentation, libraries, demos… Everything you need for faster integration.
Book a demo and tell us more about your project/issues, we’ll be happy to help!
Authors:
Evelina Georgieva, co-founder @ Pryv SA
Stephanie Tischhauser, Privacy Expert & Digital Content Writer @ Pryv SA
=====
Pryv helps life sciences and healthcare organizations preserve data privacy and rigorously manage personally identifiable information from creation, to use, sharing and disposal.
Our software accelerates patient-centric innovation and addresses the enhanced data individual’s rights under GDPR such as transparency, portability and right-to-be-forgotten.
The post The Personal Data LifeCycle, sorted out by Pryv. appeared first on Pryv.
]]>The post Data pooling: Get the most out of the data you collect appeared first on Pryv.
]]>Flip the coin and you’ll see that the true potential of the data that you collect lies in its aggregation. Your data scientists will only be able to unlock its value when identifying rich data sources, aggregating them with others, and pooling large quantities of formless data.
With Pryv.io, we enable you to pool and analyze data meaningfully.
Data pooling enables you to combine data sets coming from different sources.
Let your Data Scientists Deep Dive.
Your data scientists need data. A lot of it. They can only make discoveries while swimming in deep data pools. Let them deep-dive – ensure that their swimming pool is deep enough.
How to do so?
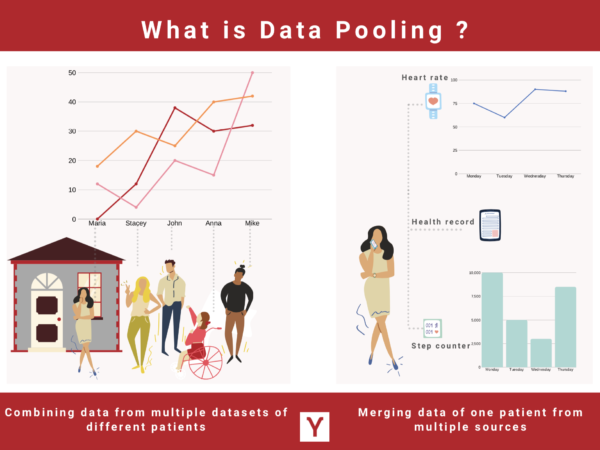
Let’s assume that you aim at developing a Digital Health platform, fed with aggregated personal data. So data pooling means that you can:
- combine together data on one individual coming from multiple sources such as medical devices, specialist clinics, health records.
- merge into one file multiple datasets from many patients coming from various countries or institutions.
In both cases, this is what makes the data pool deeper and generates value for your data scientists.
The wait is over: the icing on the cake.
Now you know why data pooling is indispensable to get valuable insight from data that you collect. Unlock your business value by ensuring that your data scientists are provided with enough data at a glance.
The best is yet to come- the Icing on the cake : Pryv.io does it for you. From data collection to data aggregation, data structure and understanding, Pryv enables you to get the most out of the data you collect. Let’s walk through an example to illustrate where Pryv.io stands and how we can help you.
It’s often that you are collecting data from different sources and that you need to share the whole or only part of the aggregated dataset with various third parties.
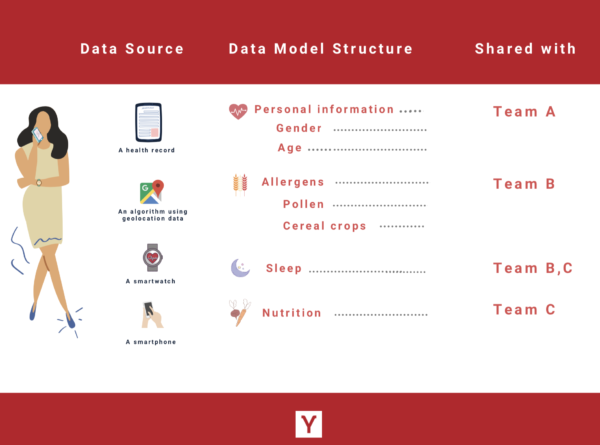
So let’s go through a basic use case, in which you are conducting a clinical trial involving hundreds of patients from different institutions. You are researching the impact of allergen exposure and nutrition diet on the sleep behavior of patients, and you’re having three different teams analyzing the collected data from different perspectives :
- Team A needs to analyze personal information from every patient (such as age, gender, ethnicity, etc);
- Team B is combining allergen exposure with sleep data to identify patterns;
- Team C is looking at the relationship between nutrition and sleep.
Already getting a headache just thinking about how to structure your data efficiently to aggregate it and share only what each of the teams need?
Pryv.io enables you to aggregate data from multiple sources and to share only what is needed.

Pryv.io has developed a tool that solves it all for you. Our aggregator allows you to pool data from multiple sources at once, and to create appropriate and up-to-date datasets with data across multiple accounts for each team to work on.
How is that?
- Pryv.io aggregator enables you to collect and aggregate any type of data from all your patients. Data from a smartphone, a smartwatch, a health record, any source of data, all in one place.
- Our data model in “streams” and “events” structures your data, and allows your patients to grant your app/or your team access to the needed streams. (more on that in this article)
- Each patient’s data subset gets aggregated into your own database and the appropriate datasets are exposed to your teams and your algorithms/apps.
- Once datasets are allocated to each team by sharing the appropriate subsets of streams, they get automatically updated. It means that as soon as new data from any patient is collected, a webhook notifies the server that fetches the data and updates the dataset for the concerned team (more on webhooks in Pryv.io here).
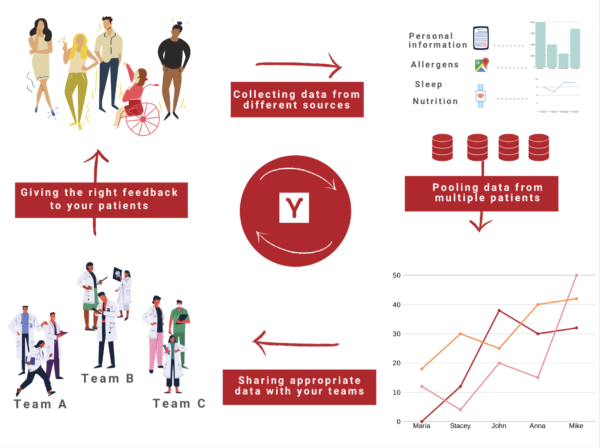
All at once, you can now collect and aggregate data coming from different sources for one to thousands of patients, and create multiple data pools so that your data scientists can work more efficiently and get the most out of your collected data. All of that while respecting the data privacy of your patients, and ensuring a trusting relationship.
It’s as simple as that, so you have one less thing to worry about and one more to benefit from: Pryv.io.
Ana @ Pryv
The post Data pooling: Get the most out of the data you collect appeared first on Pryv.
]]>The post Audit logs in Pryv.io : When every single piece of information matters appeared first on Pryv.
]]>In this article, we will show you the power of using Pryv.io data-audit to de-risk your compliance.
So what are audit logs?
Audit logs maintain a full and complete history of every change that has been made on a piece of data, by whom and when. An audit log is the simplest, yet also one of the most effective forms of tracking temporal information. Any time something significant happens, a record indicating what happened and when it happened, is generated.
What do data audits look like?
It can take many physical forms, but the most common form is a file. It must contain all relevant information concerning the sequence of activities that affected at any time a specific operation, procedure, or event in an IT system. In addition to documenting what resources were accessed, audit log entries usually include destination and source addresses, a timestamp and user login information.
Why do you need to use data-audits?
Stringent data protection regulations become a major concern to organizations. Bolstering your data management capabilities to meet compliance is a priority and business-critical.
Beyond being a good practice, using data-audits will not only allow you to keep logs of any data interactions but also to “demonstrate compliance”, which is a key point of the GDPR.
Furthermore, audit logs have taken on new importance for cybersecurity and are often the basis for diagnostic performance, error correction and security analysis.
De-risk your compliance with data-audit at Pryv.io
Audit logs keep track of details about the actions performed by your app users against Pryv.io accounts through the Pryv.io API.
In other words, it describes the source (the identifier for the action that generated this log), the type of log, the time when it was executed, the audited action (typically the API method call), the identifier for the access used to perform the audited action, and the HTTP response status resulting from the audited action.
Here is an example of a single audit log in Pryv.io :
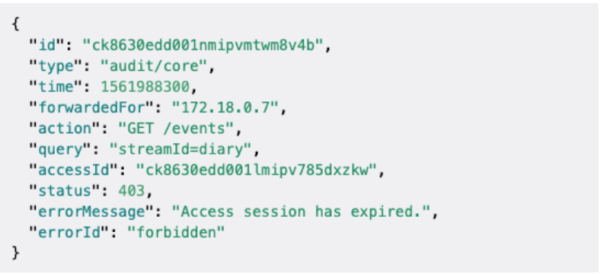
You can see that the IP address “172.18.0.7” was used to get the events from the stream “Diary” at the time 1261988300 seconds, and that the attempt was unsuccessful as the used access has expired, all of this at one glance.
Audit logging is an essential ingredient for your infrastructure. By using the capabilities of Pryv.io log management system, you are a step closer in succeeding your compliance auditing.
To learn more about how audit logging in Pryv.io can help you, check out our API reference for it.
Address existing and forthcoming data protection requirements and future-proof your regulatory compliance with Pryv.io.
The post Audit logs in Pryv.io : When every single piece of information matters appeared first on Pryv.
]]>The post Beyond data: Pryv.io helps you win users’ trust: collect and use their personal data rightly appeared first on Pryv.
]]>Today, collecting personal data is made easy, many would say.
While collecting data can be easy, getting valuable insights from it is certainly not.
Even more, managing it properly so that you win your users’ trust and stay on top of the regulations is the hard job to do.
- What if you could spend less time worrying about how to manage personal data?
- What if you could use this time to increase your users’ trust and engagement?
- What if you could focus on your own benefits and return on your data investments?
With Pryv.io, we enable you to manage personal data rightfully – from the first time and overtime.
No matter the existing and upcoming regulations on data protection, our software allows you to remain compliant at all times and to build a trustful relationship with your users.
So how does it work? Let’s walk through a basic use case to see how Pryv.io solves data privacy challenges.
Collecting personal data in real-time allows you to gain valuable insights quickly and to make decisions accordingly.
Let’s say that you have built an algorithm that computes allergen exposure based on geolocation data and displays it on your app to users and their doctors.
This involves three types of actors :
- Your app users;
- Your algorithm, that processes the geolocation data of the users and computes the allergen exposure;
- Doctors, who consult the allergen exposure data and provide feedback to the app users.
Your algorithm takes the personal geolocation data, processes it, outputs the allergen exposure and shares it with the user (patient) and doctors on the digital app at any time.
Easy? Well, sounds easy enough to collect personal data until you need to prove that you have the right to collect it and handle data privacy correctly.
- The geolocation of your user is a personal, sensitive data.
- Your user has the right to revoke his consent and to decline sharing this sensitive data with any other third-parties (such as doctors, in this use case).
However, your user really wants to use your app to help him and to be guided by his doctor about his allergen exposure. Is this possible? We made a simple way to do it.

Sensitive Personal Data Sharing, Simplified.
Only the algorithm needs to see the geolocation data, and nobody else, so why not just restrain the read access of the geolocation data to the algorithm?
And restrain the allergens data to the user and his doctor?
And oh, what if his doctor wants to communicate his feedback to the user?
…
Starts to get a bit more complex, mmh ?
Let’s draw it simply in “streams” and display the data using Pryv Data Model :
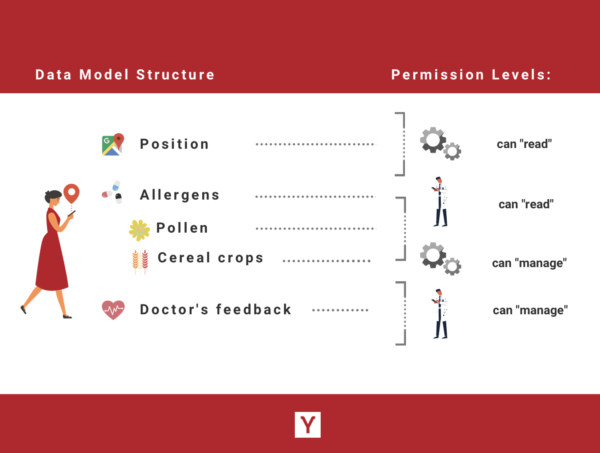
When structuring the data in “streams” (which act like folders on your computer), you will be adding “events”, corresponding to time-stamped data in the related stream, and managing the level of “access” to this stream (‘read’, ‘manage’, ‘contribute’ or ‘create-only’).
For example, the stream “Position” will only contain events of type “position/wgs84”, whereas the stream “Allergens” will contain substreams of allergens (“Pollen”, “Cereal crops”, etc) with events of type “density/kg-m3” …
Now you see how our data model in streams and events is helpful.
It has never been that easy to take and share only a piece of data, with different levels of access.
For your app, it means that: first, the data is collected, aggregated from different sources and structured in the right way in Pryv.io. Then, it enables your app users to decide what they want to share and with whom, and to revoke that access at any time. And finally, it gives you peace of mind for any data privacy regulations, as all the requirements to meet are already designed in Pryv.io.
As an app user, you decide if you :
- want the algorithm only to be able to see your geolocation?
Share the stream “Position” with a “read” level.
- want your doctor to see your allergen exposure?
Share the stream “Allergens” with a “read” level.
- want your doctor to give you feedback and advice? Share the stream “Doctor’s feedback” with a “manage” level, enabling the doctor to add his comments in newly created child streams of this stream.
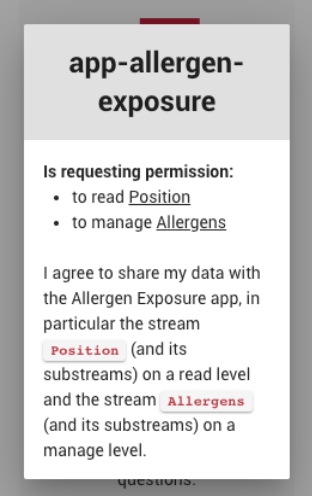
This can be all automated by creating access requests from your app. It will send a notification to your user to request access to the stream “Position” stream on a “read” level and to “Allergens” on a “manage” level.
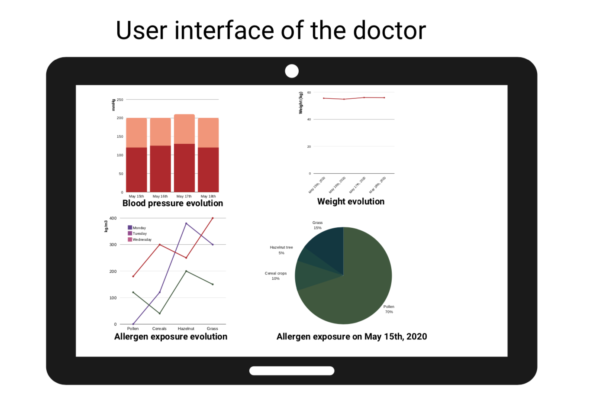
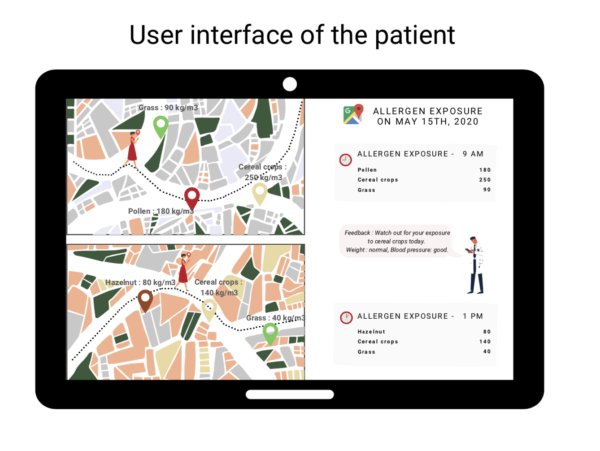
Building a Trustful Relationship with Your Users, made easy.
By structuring the data you collect in this way and sharing the data of your user at a very granular level only to authorized third-parties with the user’s explicit consent, you establish a trustful relationship.
The more trust your users have in your app, the more data they will share.
According to the data your users are willing to share, you will be able to adapt the user interfaces to the different third-parties and display only authorized data.
Respecting your user’s privacy will make your users more prone to share personal information with you.
And the more data you will get, the more you will be able to provide valuable insights for your customer.
It has never been so easy to bring confidence to your customers. Simple, fast and effective, building your own solution on top of Pryv.io ensures you a long and trusted relationship with your users. So you can spend less time worrying about how to manage personal data and use this time to increase your users’ engagement.
Now, focus on your own benefits and return on your data investments.
With Pryv.io, we enable you to manage personal data rightfully – from the first time and overtime.
Ana @ Pryv
The post Beyond data: Pryv.io helps you win users’ trust: collect and use their personal data rightly appeared first on Pryv.
]]>The post Webhooks at Pryv.io: When data ages in milliseconds, waiting is not an option. appeared first on Pryv.
]]>Fast world, fast life- technology made the world change in milliseconds. Every second, a new piece of personal information is born. It begins its long journey in this digital world from being created, updated, acknowledged … leaving digital footprints with the purpose to be transferred into valuable insight to someone. Regulators made it clear, as owners of these pieces of information, each individual (user) can execute his rights to demand their full traceability at any given time.
Wait a second?!? Sometimes even a delay of several microseconds is not acceptable.
For the app developers of personal-data fed solutions, delivering on this is challenging.
In this article, we provide you with worth-to-know insights on how Pryv.io notifies your app of any data changes from now; what are webhooks, why you’d better use them and how to integrate webhooks into your infrastructure with Pryv.io.
The wait is over : webhooks update data before you know it
If transfer of information is happening in real-time, users expect to get updates on what is being done in the blink of an eye. Having to wait until your app or your server goes to check on its own if something new happened with the data you are collecting is not acceptable anymore.
Well, this is exactly why webhooks have been created; and this is also the reason why we decided to implement them on Pryv.io. When you require real-time notifications of events, using a webhook is really your best option.
What exactly are Webhooks?
By definition, webhooks are a way to set up a push notification to a predefined URL endpoint. It is triggered by some event that one wishes to be alerted of, mostly in order to act on it. These are automated messages sent from web services when something happens.
It’s how PayPal tells user’s accounting app when their clients pay them, how MailChimp notifies their users of common events such as subscribing, unsubscribing and profile changes, how Shopify keeps some parts of their users’ commerce and fulfilment system up-to-date…and how Pryv.io notifies your app of any data changes from now.
To put it simply, webhooks act much like push notifications. Each time when a data change occurs in the account of your app users, your web service gets notified. Let’s say for example a new event related to their physical activity. As soon as the new event has been created, your web service gets a message like “Hey, something new just happened on one of the accounts !”. A data change has occurred in your users’ data, and your web service got notified about it. You can now process the fresh and up-to-date data with your algorithms.
Webhooks work the same way.
The point of contact between your server and the webhook is the URL that was provided at the creation of the webhook. You get notified of data changes in a web service using webhooks, that send an HTTP POST request to this URL with a payload similar to the notification message below :

The server which listens to the provided URL receives the request and only needs to retrieve events and streams since last change to see what’s new. Nothing left to be done.
Why use webhooks?
Having up-to-date data is crucial for your process or your algorithms to work properly. You need to have reliable information to be able to keep your algorithm at pace with data changes happening in a few seconds.
But you don’t want to have to go manually knock on the door and check whether you have some fresh information on your user’s data account, do you ? What you want, and what you actually need, is the information to come to you automatically and tell you : “There is something new waiting for you, just come and have a look.”.
Automation leads to optimization.
Still not convinced ? Here is a concrete use case that can fit the service you are offering with your digital app, your clinical trial or any research you are performing with personal data.
Let’s say that your service integrates health or personal data using your Pryv.io platform, and you’d like to allow your app users to share their data with doctors or any other third parties, and to maintain the aggregated dataset up-to-date.
You can easily do it now. Thanks to webhooks.
How ? The user first consents to give access to the doctor or any other third party to his data. Each time he records new data with your app, the data is added and stored on the dedicated Pryv.io platform. The webhook notifies the web service whenever a data change occurs, which automatically maintains the dataset up-to-date.
The doctor can then retrieve the latest data of any user and consult the updated aggregated dataset whenever he needs.
The user can revoke his consent at any time, which notifies the web service through webhooks and removes his data from the data record.
As simple as that !

Want more ?
If you are craving for more technical information about Webhooks and how to use them on Pryv.io, check out our new dedicated section about Webhooks.
The post Webhooks at Pryv.io: When data ages in milliseconds, waiting is not an option. appeared first on Pryv.
]]>The post Discover Pryv.io API and Facilitate Pryv.io integration with Postman appeared first on Pryv.
]]>- visualize how Pryv.io works,
- skip documentation reading,
- get your job done quicker!
Even more, Postman also lets you generate snippets of code that will help you further cut your overall integration time and costs while fasting your way to compliance.
The best part is that you don’t even need any programming skills to work with Postman.
So even your project manager, GDPR- or Data Protection Officer will be able to understand what we do.
Also, for those of you who are just curious to know more about our API, this is a good way to simply understand how Pryv works.
Download our newly created OpenAPI definition file & boost your way to privacy using our 5min tutorial!
Facilitate Pryv.io integration with Postman Video
More about Postman: here
The post Discover Pryv.io API and Facilitate Pryv.io integration with Postman appeared first on Pryv.
]]>The post Pryv Unleashes IoT Connectivity with High Throughput Data Ingestion appeared first on Pryv.
]]>“One of the key challenges of IoT data streams is to handle high volumes of data with fast connectivity without compromising on security.” says Stephan Bachofen, VP Software at Biovotion AG. “Pryv’s high throughput data ingestion will allow medical trackers to cope with future large volumes of telemetry data overcoming surges with guaranteed low-latency at affordable costs.”
The Healthcare industry remains among the fastest to adopt the Internet of Things.
Integrating IoT features into medical devices greatly improves the quality and effectiveness of service, bringing especially high value for the elderly people, patients with chronic conditions, and those requiring constant supervision. According to market estimates, spending on the Healthcare IoT solutions will reach 1 trillion Swiss francs by 2025 and will set the stage for highly personalised, accessible and on-time Healthcare services for everyone. Organisations need to ensure that future data conduits are powerful enough to handle and process the predicted throughput and increase in telemetry data, yet stay flexible enough to react to changing business needs.
Pryv provides a future-proof, device-ready privacy management solution handling personal data thru its lifecycle. IoT data arrives in the form of a continuous telemetric stream, is rapidly ingested, processed for authorisation and then optimally compressed in Pryv’s personal data vault for sharing and analysis.
Pryv’s purpose-built API is designed to ingest different types of high frequency data streams concurrently and efficiently.
Benchmarks performed on the beta release show notable improvements in throughput and storage density. On moderate virtualised hardware (4 cores, 14 GB RAM, 5000 IOPS), Pryv.io High Frequency stores 100’000 measures per second at approximately one byte per measure. The new release uses several advanced data compression algorithms to optimise disk usage. With an average IoT device capturing 20 sensor values every second, a single 4 cores Pryv.io machine is able to store the data produced by 2000 concurrent devices. In a standard deployment, multiple machines would be receiving the telemetric streams in parallel.
Pryv helps organisations manage personal data from creation, to use, to sharing, archival and deletion. The High Frequency release is appropriate for health applications that require near real-time experience such as in physiology monitoring, critical home care services or point-of-care diagnostic. Our adaptive privacy out-of-box solution comes integrated with a secure storage vault, fine-grained consent management and comprehensive auditing capability that radically accelerate time-to-benefit while addressing most stringent data protection requirements.
The post Pryv Unleashes IoT Connectivity with High Throughput Data Ingestion appeared first on Pryv.
]]>The post Pryv and HES-SO team up to extend HL7 FHIR data exchange with semantic interoperability appeared first on Pryv.
]]>“One of the main technology barrier for providing patient-centered healthcare is the problem that patient data is often housed in a number of disparate systems across multiple locations” says Professor Michael Schumacher. “We joined forces with Pryv to include rich semantics in the data model and automate the import of datasets to close communication gaps.”
Semantization provides interoperability at the highest level in the electronic exchange of patient information among caregivers and other authorized parties. This improves quality, safety, efficiency and efficacy of healthcare delivery. When correctly implemented, EHR interoperability ensures that providers understand the patient as an individual with a medical history and network. Its objective is to address the challenges of how healthcare systems inform various stakeholders involved in a patient’s care as well as how organizational facets of health information exchange will coordinate together for the benefit of patients.
“The inclusion of rich semantics into Pryv.io goes beyond the traditional tagging and key word classification” says Pierre-Mikael Legris, CEO of Pryv. “The eHealth unit of HES-SO Valais-Wallis is helping us to incorporate algorithms from machine learning and rule inferencing that can progressively learn the type and variety of data, and propose/assign explicit semantics as it flows through our software.”
Alongside of the R&D collaboration, HES-SO Valais Wallis is making the Pryv.io personal data management platform available to its 2’500 students and staff members. The environment is designed to accelerate digital health innovation and enable eHealth research projects such as an m-health self-monitoring solution for patients undergoing physiotherapy treatments.
About Pryv
Pryv makes essential software for data-driven healthcare innovation. Our purpose-built middleware helps organizations manage personal data from creation to use, sharing and disposal. We accelerate time to market, cut IT development costs and speed up connectivity to all data sources. Pryv addresses the enhanced citizen’s right under GDPR and turns privacy compliance into a competitive advantage. For more information: https://pryv.github.io/www
About the eHealth unit of the Institute Information Systems HES-SO Valais-Wallis
The eHealth unit is part of the Institute of Information Systems of the University of Applied Sciences and Arts Western Switzerland (HES-SO). Based in Sierre (Valais, Switzerland), the eHealth unit undertakes applied research in close collaboration with public or private companies and institutions. It has gained solid experience with complex interdisciplinary projects related to digital health, at national and international levels. The eHealth unit has for instance invested many research efforts in the development of sensor-based mHealth applications for chronic diseases (e.g. diabetes type 1 and 2). Furthermore, the unit has developed expertise in health record data interchange and the usage of standards (HL7, FHIR), as well as the development of privacy and anonymity preserving algorithms for health data exchange (Nano-Tera.ch ISyPeM2 project). It is also working on blockchain-based healthcare data management and on a prototype of a framework for managing and sharing EMR data for cancer patient care. It is investing many efforts in personalized health support, such as for coaching in physiotherapy, or smoking cessation programs run on social networks with chatbot supports.
The post Pryv and HES-SO team up to extend HL7 FHIR data exchange with semantic interoperability appeared first on Pryv.
]]>